Appearance
Compounds and strings
复合和字符串
复合
符合类型是由其他类型组成,经典例子就是结构体struct和枚举enum。Rust 主要有两种复合类型:元组(tuples)和数组(arrays)。
元组 (Tuples)
- 元组是一个可以包含多个类型的值的集合。
- 元组的大小在定义时是固定的。
- 访问元组中的值是通过索引来实现的。
例如:
let tup: (i32, f64, u8) = (500, 6.4, 1);<!--在上面的代码中,`tup` 是一个包含三个不同类型的元素的元组。-->
()它是一个特殊的类型,表示没有任何有意义的值。这可以看作是一个零元素的元组。
数组 (Arrays)
- 数组是一个包含多个相同类型值的集合。
- 数组的大小在定义时也是固定的。
- 数组用于需要将多个相同类型的值存储在一起的情况,而且你知道在编译时它们的确切数量。
例如:
let arr: [i32; 5] = [1, 2, 3, 4, 5];<!--<u>在上面的代码中,`arr` 是一个包含五个 `i32` 类型元素的数组</u>-->
数组和元组之间的联系和区别
区别: 元素类型:
数组:数组中的所有元素都必须是相同的类型。 元组:元组中的元素可以是不同的类型。 大小:
数组:数组的大小是固定的,这意味着一旦定义了数组的长度,你不能改变它。 元组:元组的大小也是固定的,一旦定义,你不能更改它。但与数组不同的是,元组的长度不是其定义的一部分,所以你可以有多个不同长度的元组而不需要使用不同的类型名称。 访问元素:
数组:你使用索引来访问数组的元素,例如 arr[0]。 元组:你可以使用点号和索引来访问元组的元素,例如 tup.0。 主要用途:
数组:当你需要存储多个相同类型的元素时使用数组。 元组:当你需要组合不同类型的值时使用元组。 联系: 固定大小:两者都有固定的大小,这意味着一旦定义,你不能更改它们的大小。
在栈上存储:数组和元组中的元素通常都是在栈上分配的,除非它们被包含在堆上分配的数据结构中。
模式匹配:在 Rust 中,你可以使用模式匹配来解构数组和元组,这使得你可以方便地访问它们的内容。
内存连续性:在内存中,数组和元组的元素都是连续存储的。
复合的作用:
- 组织数据:复合类型允许你将相关的数据组织在一起,而不是每个数据都单独声明为变量。
- 固定大小的集合:与其他语言中的列表或动态数组不同,Rust 的元组和数组在定义时大小是固定的,这意味着它们在堆上不会动态增长或缩小。
- 类型安全:特别是在元组中,你可以在一个集合中存储不同类型的值,并在编译时确保每个元素的类型正确。
- 效率:由于它们的大小是固定的,数组特别是在性能关键的场景中,可以提供更高的效率,因为它们可以在栈上分配。
Rust 中的复合类型提供了一种在一个集合中组织和处理多个值的方式,这些值可以是相同的类型(如数组)或不同的类型(如元组)
rust语言圣经中举例:
例如平面上的一个点 point(x, y),它由两个数值类型的值 x 和 y 组合而来。我们无法单独去维护这两个数值,因为单独一个 x 或者 y 是含义不完整的,无法标识平面上的一个点,应该把它们看作一个整体去理解和处理。
#![allow(unused_variables)]
type File = String;
fn open(f: &mut File) -> bool {
true
}
fn close(f: &mut File) -> bool {
true
}
#[allow(dead_code)]
fn read(f: &mut File, save_to: &mut Vec<u8>) -> ! {
unimplemented!()
}
fn main() {
let mut f1 = File::from("f1.txt");
open(&mut f1);
//read(&mut f1, &mut vec![]);
close(&mut f1);
}
代码解释:
<!--//#![allow(unused_variables)] 属性标记,该标记会告诉编译器忽略未使用的变量,不要抛出 warning 警告,read 函数也非常有趣,它返回一个 ! 类型,这个表明该函数是一个发散函数,不会返回任何值,包括 ()。unimplemented!() 告诉编译器该函数尚未实现,unimplemented!() 标记通常意味着我们期望快速完成主要代码,回头再通过搜索这些标记来完成次要代码,类似的标记还有 todo!(),当代码执行到这种未实现的地方时,程序会直接报错。你可以反注释 read(&mut f1, &mut vec![])。-->
字符串
Rust 中的字符串处理有些独特,因为它为了确保内存安全和并发安全采取了严格的措施。在 Rust 中,主要有两种字符串类型:String 和 str。这两种类型分别对应于可变字符串和不可变字符串。
切片slice
在开始记笔记之前先引用”rust语言圣经“中一个案例去了解下切片。
首先来看段很简单的代码:(greet 函数接受一个字符串类型的 name 参数,然后打印到终端控制台中,非常好理解)
fn main() {
let my_name = "Pascal";
greet(my_name);
}
fn greet(name: String) {
println!("Hello, {}!", name);
}
你们猜猜,这段代码能否通过编译?
error[E0308]: mismatched types
--> src/main.rs:3:11
|
3 | greet(my_name);
| ^^^^^^^
| |
| expected struct `std::string::String`, found `&str`
| help: try using a conversion method: `my_name.to_string()`
error: aborting due to previous error
Bingo,果然报错了,编译器提示 greet 函数需要一个 String 类型的字符串,却传入了一个 &str 类型的字符串,相信读者心中现在一定有几头草泥马呼啸而过,怎么字符串也能整出这么多花活?
在讲解字符串之前,先来看看什么是切片?切片的半官方定义是:对集合中一系列连续元素的引用。
是一个没有所有权的数据类型,对于字符串而言,切片就是对 String 类型中某一部分的引用。
再者说:切片可以用于访问数组、字符串或其他集合的一部分数据,而无需拷贝。它们常用于函数参数,以避免数据的所有权移动或不必要的数据复制。
就是大致这样:
#![allow(unused)]
fn main() {
let s = String::from("hello world");
let hello = &s[0..5];
let world = &s[6..11];
}代码解释
<!--#![allow(unused)] 是一个编译器指令,告诉 Rust 的编译器忽略未使用的代码的警告。在这种情况下,由于你只是声明了 hello 和 world 但没有实际使用它们,所以编译器会产生警告。通过添加 #![allow(unused)],这些警告将被抑制。这个属性通常在开发过程中的某些阶段使用,例如当你正在编写一部分代码但尚未完成,或者当你想临时禁用某些警告时。在生产代码中,通常建议处理这些警告,而不是简单地禁用它们,以确保代码的质量和维护性。-->
<!--这段代码写的是创建了一个 String 类型的变量 s,并初始化为 "hello world"。--> <!--使用字符串切片语法,从 s 中提取 "hello" 和 "world",并分别将它们存储在变量 hello 和 world 中。-->
<!--创建切片语法就在于此,而使用方括号包括了什么时候和什么时候结束,即[ 开始索引..结束索引 ]。这里的开始索引就是在说明第一个元素开始的位置,结束索引便是你想结束的位置-->
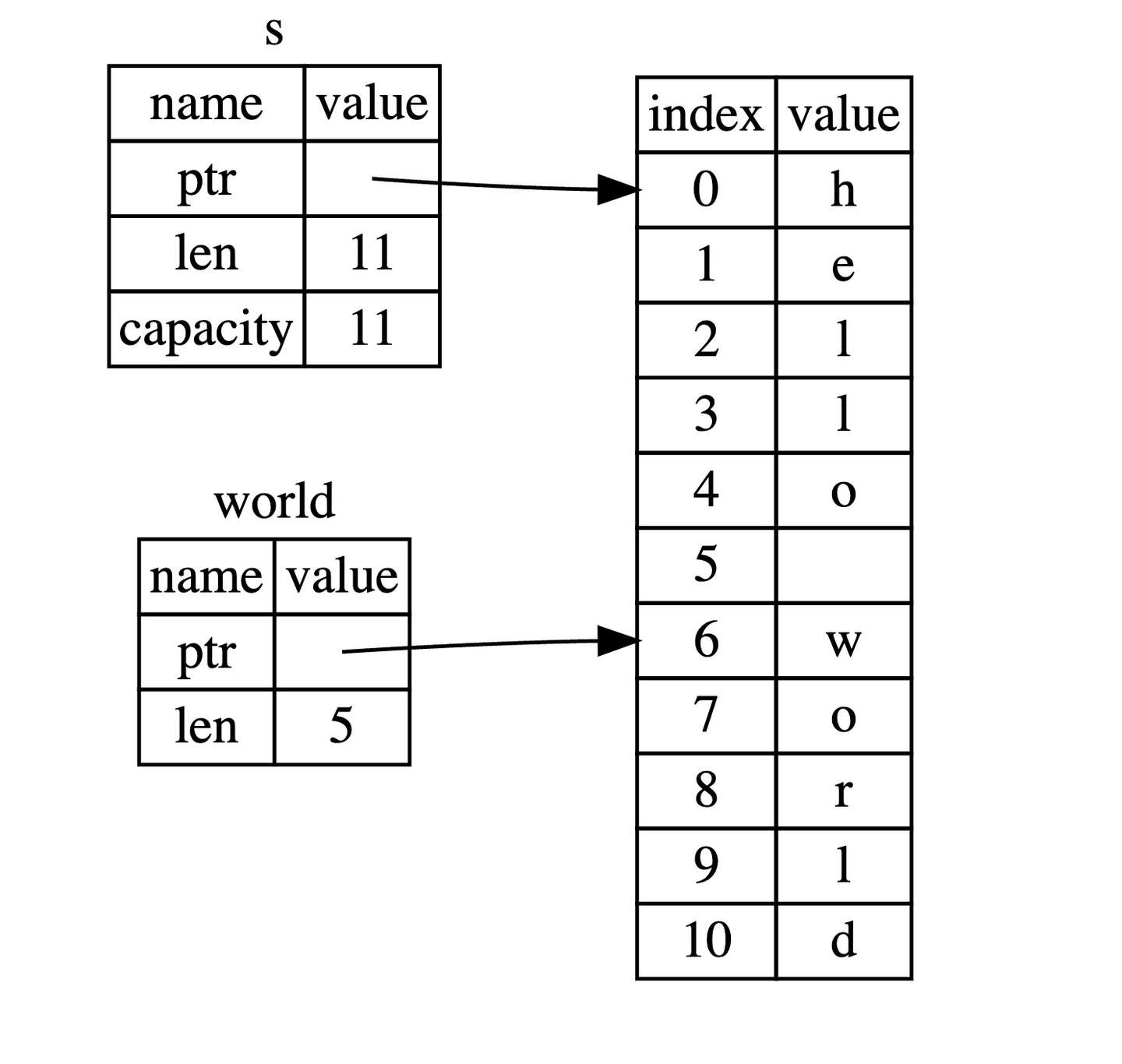
rust语言圣经解释:
hello 没有引用整个 String s,而是引用了 s 的一部分内容,通过 [0..5] 的方式来指定。
对于 let world = &s[6..11]; 来说,world 是一个切片,该切片的指针指向 s 的第 7 个字节(索引从 0 开始, 6 是第 7 个字节),且该切片的长度是 5 个字节。
rust程序设计与语言解释:
这类似于引用整个 String 不过带有额外的 [0..5] 部分。它不是对整个 String 的引用,而是对部分 String 的引用。
可以使用一个由中括号中的 [starting_index..ending_index] 指定的 range 创建一个 slice,其中 starting_index 是 slice 的第一个位置,ending_index 则是 slice 最后一个位置的后一个值。在其内部,slice 的数据结构存储了 slice 的开始位置和长度,长度对应于 ending_index 减去 starting_index 的值。所以对于 let world = &s[6..11]; 的情况,world 将是一个包含指向 s 索引 6 的指针和长度值 5 的 slice。
切片要只是包括string的最后一个字节,便可以:
let s = String::from("hello");
let len = s.len();
let slice = &s[4..len];
let slice = &s[4..];代码解释
let s = String::from("hello");这行代码创建了一个 String 类型的变量 s 并初始化为 "hello"。
let len = s.len();这行代码获取字符串 s 的长度并存储在变量 len 中。对于字符串 "hello",其长度为 5。
Len(): 这是一个方法调用。在这里,你调用了 String 类型的 len 方法。这个方法返回字符串中字节的数量。 对于字符串 "hello",它是由5个字符组成的,而且每个字符都是一个字节(在这种情况下,因为这些字符都是 ASCII 字符),所以 s.len() 返回5。 let len = ...;:
使用 let 关键字,你创建了一个新的不可变变量 len。 你将 s.len() 的返回值(也就是5)赋给了这个新变量 len。 总的来说,第二行代码做的事情是:调用字符串 s 的 len 方法来获取其长度,并将这个长度值存储在一个新的变量 len 中。现在,变量 len 包含数字5。
let slice = &s[4..len];这行代码从 s 中提取一个切片,开始于索引 4(包含)并结束于索引 len。由于 len 是 5,这意味着切片结束于字符串的末尾。结果是,slice 包含字符串 "o"。
let slice = &s[4..];这行代码也是从 s 中提取一个切片,但结束索引被省略了,这意味着它默认切片到字符串的末尾。这与前面的切片一样,slice 包含字符串 "o"。
使用范围的结束索引(如 ..len)或省略结束索引(如 4..)都是达到相同效果的有效方式。省略结束索引通常更简洁,尤其是当你想切片到字符串的末尾时。
切片类型&String和&str
Rust 中有几种不同的切片类型,但最常见的是字符串切片 (&str) 和数组切片 (&[T])。
切片的几个关键点:
- 不拥有数据:切片只是对原始数据的引用,不拥有这些数据。这意味着切片的生命周期不能超过它引用的数据。
- 动态大小:切片的大小在运行时是可知的,但在编译时不是。这与数组不同,数组的大小在编译时是已知的。
- 边界检查:当使用切片时,Rust 会执行边界检查。尝试创建超出原始数据边界的切片会导致编译时错误或运行时 panic。
字符串切片的类型标识是 &str,因此我们可以这样声明一个函数,输入 String 类型,返回它的切片:
fn first_word(s: &String) -> &str。
这个函数在字符串上使用切片来实现
fn first_word(s: &String) -> &str {
let bytes = s.as_bytes(); // 将字符串转换为字节数组
for (i, &byte) in bytes.iter().enumerate() {
if byte == b' ' {
return &s[0..i]; // 返回从开头到第一个空格之前的切片
}
}
&s[..] // 如果没有空格,则返回整个字符串的切片
}
同理有了切片就可以写出这样的代码:
fn main() {
let mut s = String::from("hello world");
let word = first_word(&s);
s.clear(); // error!
println!("the first word is: {}", word);
}
fn first_word(s: &String) -> &str {
&s[..1]
}在报错界面会出现这样的问题
error[E0502]: cannot borrow `s` as mutable because it is also borrowed as immutable
--> src/main.rs:18:5
|
16 | let word = first_word(&s);
| -- immutable borrow occurs here
17 |
18 | s.clear(); // error!
| ^^^^^^^^^ mutable borrow occurs here
19 |
20 | println!("the first word is: {}", word);
| ---- immutable borrow later used here
<!--这里如果试图在调用 `first_word` 函数后使用 `s.clear()` 来清空字符串 `s`。然而,这会导致编译错误,因为在 `first_word` 函数中返回了字符串 `s` 的切片,这个切片引用了原始字符串的数据,一旦清空了原始字符串,这个切片就会变得无效。-->
<!--在Rust中,引用和借用规则非常严格,以确保安全性。在这种情况下,可以考虑使用不可变引用来避免这个问题,同时也需要调整 `first_word` 函数,以便返回一个字符串切片,而不是 `&s[..1]` 这样的硬编码切片。-->
rust语言圣经:
回忆一下借用的规则:当我们已经有了可变借用时,就无法再拥有不可变的借用。因为 clear 需要清空改变 String,因此它需要一个可变借用(利用 VSCode 可以看到该方法的声明是 pub fn clear(&mut self) ,参数是对自身的可变借用 );而之后的 println! 又使用了不可变借用,也就是在 s.clear() 处可变借用与不可变借用试图同时生效,因此编译无法通过。
从上述代码可以看出,Rust 不仅让我们的 API 更加容易使用,而且也在编译期就消除了大量错误!之前提到过字符串字面量,但是没有提到它的类型:
let s = "Hello, world!";实际上,s 的类型是 &str,因此你也可以这样声明:
let s: &str = "Hello, world!";&String:
&String是对String类型的引用。String是一个可变、拥有(owned)的字符串类型,而&String表示对这个可变字符串的不可变引用。- 因为
&String是对String的引用,所以它可以访问String上的所有方法和功能。您可以使用&String来读取字符串数据,但不能修改它,因为它是不可变的引用。
&str:
&str是对字符串切片的引用。字符串切片是一个不可变的引用,可以引用一部分字符串数据,而不需要拥有整个字符串。&str可以引用任何包含文本数据的类型,包括String、&str、字面字符串(例如"hello"),甚至更多。这使得它非常灵活。
二者之间的区别:
&String是对String类型的引用,而&str是对字符串切片的引用。&String只能引用String类型的数据,而&str可以引用各种字符串数据。&String是不可变引用,不允许修改字符串数据,而&str也是不可变引用,同样不允许修改字符串数据。
在Rust中,通常会使用 &str 来引用字符串数据,因为它更通用,并且可以用于多种不同的字符串类型。但在某些情况下,需要明确使用 &String,例如,如果需要传递一个 String 的引用作为参数,并且不允许修改原始字符串。
String:
String是一个可增长的、可变的、有所有权的、UTF-8 编码的字符串类型。- 它是存储在堆上的,并可以调整其大小。
- 这是你创建和修改字符串时使用的主要类型。
示例:
let mut s = String::from("hello"); s.push_str(", world!"); // 在字符串的末尾追加文字str:
str是一个不可变的固定大小的字符串切片。- 它通常以其借用的形式出现,称为
&str。 - 它是字符串数据的视图,而不是实际的所有者。
示例:
let s: &str = "hello world";
\